業務背景
不管是制造業還是化工行業,對于成本或產量控制、預測、決策都是生產管理中的重要組成部分。以成本控制為例,過去人們對成本控制的認識比較狹隘,傳統的成本控制范圍局限于制造產品的過程,例如對成本形成過程中一些耗費指標的控制,使它不超過定額預算,如果發生差異,進行差異計算和差異分析,以達到降低成本的目的。所以,傳統成本控制重點在生產過程中的差異計算和結束生產過程后的差異分析,是一種消極的成本控制。同時,企業耗費大量人力,物力收集的數據及指標信息并沒有得到很好的利用,只是停留在表面的分析。而借助國工數據大腦平臺的多元線性回歸分析算法,不但可以做到對成本的事先控制,即對企業未來幾年的成本進行預測,還可以及早發現企業投入的成本不足或成本過剩的現象,幫助組織明確未來成本需求趨勢,做好成本規劃工作,從而進行準確決策;而且可以復用歷史成本數據深度挖掘出有用的信息,探索出具有一般規律性和普遍適用性的成果。
多元線性回歸定義
回歸分析是作為數據科學家需要掌握的第一個算法,是數據分析中最基礎最重要的分析工具,絕大多數的數據分析問題,都可以使用回歸的思想來解決。回歸分析的任務就是,通過研究自變量X和因變量Y的數學關系式進而達到通過X去預測Y的目的,它是數據分析中最常用的預測建模技術之一。即使在今天,大多數公司都使用回歸技術來實現大規模決策。其中包括了一元線性回歸方法、多元線性回歸方法和非線性回歸方法等。(線性指的是X、Y之間呈線性關系,不管X取什么值,都能在這條回歸直線上找到對應的Y,如圖1,只要輸入X,Y的樣本數據,數據大腦中的擬合回歸算法就能得到相應的回歸直線)
圖1
界定線性回歸是否為多元,主要看自變量(即X)的個數,若自變量個數在兩個及其以上,則稱其為多元線性回歸,顯然若自變量個數有且只有一個,稱為一元線性回歸。多元線性回歸的基本原理和一元線性回歸完全相同,區別只在于自變量的個數。
在實際中,一個指標的影響因素通常不止一個,而是有若干個重要因素共同作用才導致事物的發展變化,因此在實際分析時多考慮多元回歸分析,本文以較為復雜的多元線性回歸為例。多元線性回歸模型的一般形式為:
Y=a0+a1*X1+a2*X2+a3*X3…
Y指的是因變量,即我們關注的指標(成本或產量等);X指的是影響Y的因素。a1,a2,a3……指的是影響程度的大小(又稱回歸系數大小)。
回歸分析的應用
回歸分析用于在許多業務情況下做出決策。回歸分析有三個主要應用:
1.解釋企業理解困難的事情。例如,為什么在上一季度的營業額有所下降。
2.預測重要的商業趨勢。例如,明年會要求他們的產品看起來像什么?
3.選擇不同的替代方案。例如,我們應該選擇原料A還是原料B?
進行預測的前提
當我們求出回歸模型的具體表達式時,還需要進行統計意義檢驗,通過檢驗才能使用該模型進行預測。主要包括:擬合優度檢驗、回歸模型的總體顯著性檢驗和回歸系數的顯著性檢驗等。
1. 擬合優度檢驗
擬合優度是指擬合的回歸模型與樣本觀測值之間的接近程度。即衡量一個回歸模型做的好不好的指標。用決定系數(R-sq)表示,其數值區間為 0 ~ 1,越接近1,說明模型擬合得越好。判斷標準為:大于或等于0.7,認為擬合優度較好;在0.35~0.7之間,認為擬合優度較普通;小于0.35,認為擬合優度較差。
2.回歸方程的顯著性檢驗
即檢驗整個回歸方程的顯著性,或者說評價所有自變量x整體與因變量Y的線性關系是否密切,整個回歸方程本身是否有效。通常采用F檢驗。
3.回歸系數的顯著性
若方程通過顯著性檢驗,并不意味著每個自變量對y的影響都顯著,所以就需要我們對每個自變量進行顯著性檢驗。若某個自變量系數對y影響不顯著,即無關的變量。我們需要從回歸方程中將其剔除。通常采用t檢驗。
應用場景
成本高低不僅影響著化工行業企業的利潤,更是其公司發展壯大的一個制約因素。某有機新材料企業想要減少化學反應中的原料剩余并預測在某種反應參數變量取值下的原料剩余。原料剩余越少,成本利用率越高。把我們想要研究的對象原料剩余(Y)作為因變量,選取了4個主要影響因素:原料A的SM(X1);原料B的硝酸(X2);溫度(X3);反應時間(X4)。并進行22次試驗。基于22次實驗數據進行多元線性回歸。
初步得到線性回歸方程:Y=a0+a1*X1+a2*X2+a3*X3+a4*X4。
首先,利用數據大腦中的多元線性回歸組件,就可得到回歸系數:a1,a2,a3,a4的值。即把多元線性回歸組件拖到到工作面板,配置數據及組件參數:將因變量和4個自變量分別拖到對應的區域。過程如圖1:
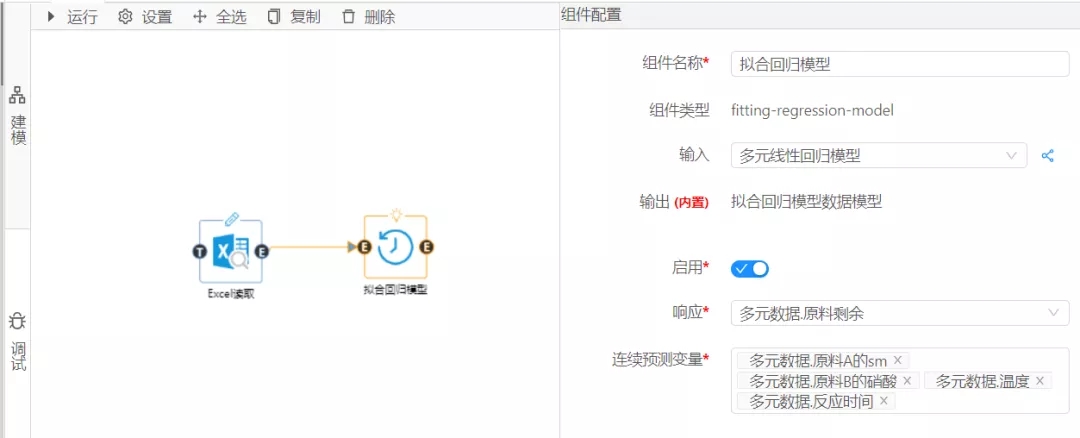
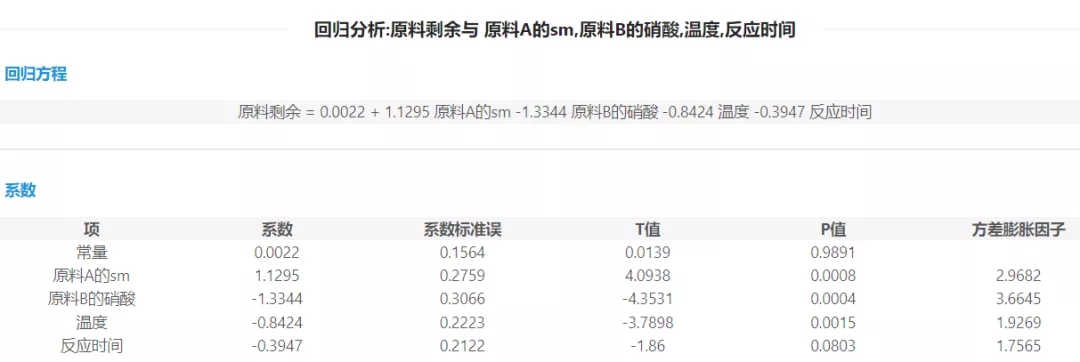

圖2

圖3
由圖2可知,關于擬合優度檢驗方面,決定系數R-sq(即R方)=0.7526,說明該模型擬合優度較好,因變量Y與自變量X1,X2,X3,X4具有較高的線性相關關系。從圖3可知:對于F檢驗,查F分布表可知,顯著性水平為0.1所對應的F臨界值是2.31,F檢驗統計量的值為5.5,故F統計量的值>臨界值,拒絕原假設。說明整個回歸模型是有效的,所有自變量整體對Y有影響。對于t檢驗,由圖2 顯示,在0.1的顯著性水平下,四個自變量的p值分別為: p1=0008;p2=0.004;p3=0.0015;p4=0.0803,均小于0.1,故拒絕原假設,進一步表明每一個自變量對Y有顯著影響。綜上,所有結果顯示此回歸模型通過了統計意義的檢驗,說明此四元線性回歸模型是成立的,可以用于預測。已知a1=1.130,a2=-1.334;a3=-0.842;a4=-0.395。最終的多元線性回歸方程為:Y=0.002+1.1295 X1-1.3344 X2-0.8424X3-0.395 X4此方程的意義是:在假定其它自變量不變的情況下,原料A的SM(X1)每增長1g,原料剩余就增長1.1295g;在假定其它自變量不變的情況下,原料B的硝酸(X2)每增長1g,原料剩余就減少1.3344g;在假定其它自變量不變的情況下,溫度(X3)每提高1攝氏度,原料剩余就減少0.8424g;在假定其它變量不變的情況下,反應時間(X4)每提高1秒,原料剩余就減少0.395g;同時,回歸系數a的絕對值越大,對Y的影響越大,可以看出a2的絕對值最大,為1.334。在決策方面,若該企業想減少原料剩余率,應當多關注原料B的情況。在預測方面:若下一次實驗時,假設X1=1.260,X2=-0.371,X3=-0.670;X4=0.770,則Y的預測值=0.002+1.1295*1.260-1.3344*(-0.371)-0.8424*(-0.670)-0.3947*0.770=2.179(g)。即原料剩余為2.179g,該企業可以將其與上一次實驗進行比較,從而進行相應的決策。
 2023-09-28
月圓人圓,國工與您賀中秋迎國慶!
2023-09-28
月圓人圓,國工與您賀中秋迎國慶!
中秋節是中國傳統節日之一,也是一年中最重要、最盛大的節日之一。在這一天,以明亮的月亮和家人團聚為特點,承載著人們無盡的思念和美好的祝福。 國慶、中秋兩節遇, 合家團圓精神俱。 團團圓圓過中秋, 歡歡喜喜
 2023-09-01
國工智能與鎂伽科技啟動戰略合作
2023-09-01
國工智能與鎂伽科技啟動戰略合作
2023年8月28日,國工智能與鎂伽科技舉行戰略合作簽約儀式,國工智能董事長柳彥宏與鎂伽科技創始人兼首席執行官黃瑜清先生代表雙方簽訂正式戰略合作協議,標志著AI輔助化工研發領先者、智能自動化實驗室引領者開啟強強聯合發展之路。&n
 2023-05-30
點亮創新發展精神火炬,勇攀人工智能科技高峰
2023-05-30
點亮創新發展精神火炬,勇攀人工智能科技高峰
創新是一個民族進步的靈魂,是一個國家興旺發達的不竭動力,也是中華民族最深沉的民族稟賦。在激烈的國際競爭中,惟創新者進,惟創新者強,惟創新者勝。 5月27日
4月6日,陜西2023年一季度重點項目觀摩活動走進渭南。當日,觀摩組深入蒲城海泰高端液晶顯示材料生產項目等重點項目建設現場進行觀摩。 作為國工智能的重要合作伙伴,近年來,

